Datasets in Iris¶
The DiffractionDataset object¶
The DiffractionDataset object is the basis for iris’s interaction with
ultrafast electron diffraction data. DiffractionDataset objects are simply
HDF5 files with a specific layout, and associated methods:
from iris import DiffractionDataset
import h5py
assert issubclass(DiffractionDataset, h5py.File) # yep
You can take a look at h5py’s documentation to familiarize yourself
with h5py.File.
You can also use other HDF5 bindings to inspect DiffractionDataset instances.
Creating a DiffractionDataset¶
An easy way to create a DiffractionDataset is through the DiffractionDataset.from_collection() method, which
saves diffraction patterns and metadata:
- classmethod DiffractionDataset.from_collection(patterns, filename, time_points, metadata, valid_mask=None, dtype=None, ckwargs=None, callback=None, **kwargs)
Create a DiffractionDataset from a collection of diffraction patterns and metadata.
- Parameters:
patterns (iterable of ndarray or ndarray) – Diffraction patterns. These should be in the same order as
time_points. Note that the iterable can be a generator, in which case it will be consumed.filename (str or path-like) – Path to the assembled DiffractionDataset.
time_points (array_like, shape (N,)) – Time-points of the diffraction patterns, in picoseconds.
metadata (dict) – Valid keys are contained in
DiffractionDataset.valid_metadata.valid_mask (ndarray or None, optional) – Boolean array that evaluates to True on valid pixels. This information is useful in cases where a beamblock is used.
dtype (dtype or None, optional) – Patterns will be cast to
dtype. If None (default),dtypewill be set to the same data-type as the first pattern inpatterns.ckwargs (dict, optional) – HDF5 compression keyword arguments. Refer to
h5py’s documentation for details. Default is to use the lzf compression pipeline.callback (callable or None, optional) – Callable that takes an int between 0 and 99. This can be used for progress update when
patternsis a generator and involves large computations.kwargs – Keywords are passed to
h5py.Fileconstructor. Default is file-mode ‘x’, which raises error if file already exists. Default libver is ‘latest’.
- Returns:
dataset
- Return type:
The required metadata that must be passed to DiffractionDataset.from_collection() is also listed in
DiffractionDataset.valid_metadata. Metadata not listed in DiffractionDataset.valid_metadata
will be ignored.
An other possibility is to create a DiffractionDataset from a AbstractRawDataset subclass using the
DiffractionDataset.from_raw() method :
- classmethod DiffractionDataset.from_raw(raw, filename, exclude_scans=None, valid_mask=None, processes=1, callback=None, align=True, normalize=True, ckwargs=None, dtype=None, **kwargs)¶
Create a DiffractionDataset from a subclass of AbstractRawDataset.
- Parameters:
raw (AbstractRawDataset instance) – Raw dataset instance.
filename (str or path-like) – Path to the assembled DiffractionDataset.
exclude_scans (iterable of ints or None, optional) – Scans to exclude from the processing. Default is to include all scans.
valid_mask (ndarray or None, optional) – Boolean array that evaluates to True on valid pixels. This information is useful in cases where a beamblock is used.
processes (int or None, optional) – Number of Processes to spawn for processing. Default is number of available CPU cores.
callback (callable or None, optional) – Callable that takes an int between 0 and 99. This can be used for progress update.
align (bool, optional) – If True (default), raw images will be aligned on a per-scan basis.
normalize (bool, optional) – If True, images within a scan are normalized to the same integrated diffracted intensity.
ckwargs (dict or None, optional) – HDF5 compression keyword arguments. Refer to
h5py’s documentation for details.dtype (dtype or None, optional) – Patterns will be cast to
dtype. If None (default),dtypewill be set to the same data-type as the first pattern inpatterns.kwargs – Keywords are passed to
h5py.Fileconstructor. Default is file-mode ‘x’, which raises error if file already exists.
- Returns:
dataset
- Return type:
See also
open_rawopen raw datasets by guessing the appropriate format based on available plug-ins.
- Raises:
IOError – If the filename is already associated with a file.
Important Methods for the DiffractionDataset¶
The following three methods are the bread-and-butter of interacting with data. See the API section for a complete description.
- DiffractionDataset.diff_data(timedelay, relative=False, out=None)
Returns diffraction data at a specific time-delay.
- Parameters:
timdelay (float or None) – Timedelay [ps]. If None, the entire block is returned.
relative (bool, optional) – If True, data is returned relative to the average of all diffraction patterns before photoexcitation.
out (ndarray or None, optional) – If an out ndarray is provided, h5py can avoid making intermediate copies.
- Returns:
arr – Time-delay data. If
outis provided,arris a view intoout.- Return type:
ndarray
- Raises:
ValueError – If timedelay does not exist.
- DiffractionDataset.diff_eq()
Returns the averaged diffraction pattern for all times before photoexcitation. In case no data is available before photoexcitation, an array of zeros is returned.
If the dataset was opened with writing access, the result of this function is cached to file. It will be recomputed as needed.
Time-zero can be adjusted using the
shift_time_zeromethod.- Returns:
I – Diffracted intensity [counts]
- Return type:
ndarray, ndim 2
- DiffractionDataset.time_series(rect, relative=False, out=None)
Integrated intensity over time inside bounds.
- Parameters:
rect (4-tuple of ints) – Bounds of the region in px. Bounds are specified as [row1, row2, col1, col2]
relative (bool, optional) – If True, data is returned relative to the average of all diffraction patterns before photoexcitation.
out (ndarray or None, optional) – 1-D ndarray in which to store the results. The shape should be compatible with
(len(time_points),)
- Returns:
out
- Return type:
ndarray, ndim 1
See also
time_series_selectionintensity integration using arbitrary selections.
- DiffractionDataset.time_series_selection(selection, relative=False, out=None)
Integrated intensity over time according to some arbitrary selection. This is a generalization of the
DiffractionDataset.time_seriesmethod, which is much faster, but limited to rectangular selections.Added in version 5.2.1.
- Parameters:
selection (skued.Selection or ndarray, dtype bool, shape (N,M)) – A selection mask that dictates the regions to integrate in each scattering patterns. In the case selection is an array, an ArbirarySelection will be used. Performance may be degraded. Selection mask evaluating to
Truein the regions to integrate. The selection must be the same shape as one scattering pattern (i.e. two-dimensional).relative (bool, optional) – If True, data is returned relative to the average of all diffraction patterns before photoexcitation.
out (ndarray or None, optional) – 1-D ndarray in which to store the results. The shape should be compatible with
(len(time_points),)
- Returns:
out
- Return type:
ndarray, ndim 1
- Raises:
ValueError – if the shape of
maskdoes not match the scattering patterns.
See also
time_seriesintegrated intensity in a rectangle.
The PowderDiffractionDataset object¶
For polycrystalline data, we can define more data structures and methods. A PowderDiffractionDataset is a strict
subclass of a DiffractionDataset, and hence all methods previously described are also available.
Specializing a DiffractionDataset object into a PowderDiffractionDataset is done as follows:
from iris import PowderDiffractionDataset
dataset_path = 'C:\\path_do_dataset.hdf5' # DiffractionDataset already exists
with PowderDiffractionDataset.from_dataset(dataset_path, center) as dset:
# Do computation
Important Methods for the PowderDiffractionDataset¶
The following methods are specific to polycrystalline diffraction data. See the API section for a complete description.
- PowderDiffractionDataset.powder_eq(bgr=False)
Returns the average powder diffraction pattern for all times before photoexcitation. In case no data is available before photoexcitation, an array of zeros is returned.
- Parameters:
bgr (bool) – If True, background is removed.
- Returns:
I – Diffracted intensity [counts]
- Return type:
ndarray, shape (N,)
- PowderDiffractionDataset.powder_data(timedelay, bgr=False, relative=False, out=None)
Returns the angular average data from scan-averaged diffraction patterns.
- Parameters:
timdelay (float or None) – Time-delay [ps]. If None, the entire block is returned.
bgr (bool, optional) – If True, background is removed.
relative (bool, optional) – If True, data is returned relative to the average of all diffraction patterns before photoexcitation.
out (ndarray or None, optional) – If an out ndarray is provided, h5py can avoid making intermediate copies.
- Returns:
I – Diffracted intensity [counts]
- Return type:
ndarray, shape (N,) or (N,M)
- PowderDiffractionDataset.powder_calq(crystal, peak_indices, miller_indices)
Determine the scattering vector q corresponding to a polycrystalline diffraction pattern and a known crystal structure.
For best results, multiple peaks (and corresponding Miller indices) should be provided; the absolute minimum is two.
- Parameters:
crystal (skued.Crystal instance) – Crystal that gave rise to the diffraction data.
peak_indices (n-tuple of ints) – Array index location of diffraction peaks. For best results, peaks should be well-separated. More than two peaks can be used.
miller_indices (iterable of 3-tuples) – Indices associated with the peaks of
peak_indices. More than two peaks can be used. E.g.indices = [(2,2,0), (-3,0,2)]
- Raises:
ValueError – if the number of peak indices does not match the number of Miller indices, or if the number of peaks given is lower than two.
IOError – If the filename is already associated with a file.
- PowderDiffractionDataset.compute_baseline(first_stage, wavelet, max_iter=50, level=None, **kwargs)
Compute and save the baseline computed based on the dual-tree complex wavelet transform. All keyword arguments are passed to scikit-ued’s baseline_dt function.
- Parameters:
first_stage (str, optional) – Wavelet to use for the first stage. See
skued.available_first_stage_filters()for a list of suitable argumentswavelet (str, optional) – Wavelet to use in stages > 1. Must be appropriate for the dual-tree complex wavelet transform. See
skued.available_dt_filters()for possible values.max_iter (int, optional)
level (int or None, optional) – If None (default), maximum level is used.
- Raises:
IOError – If the filename is already associated with a file.
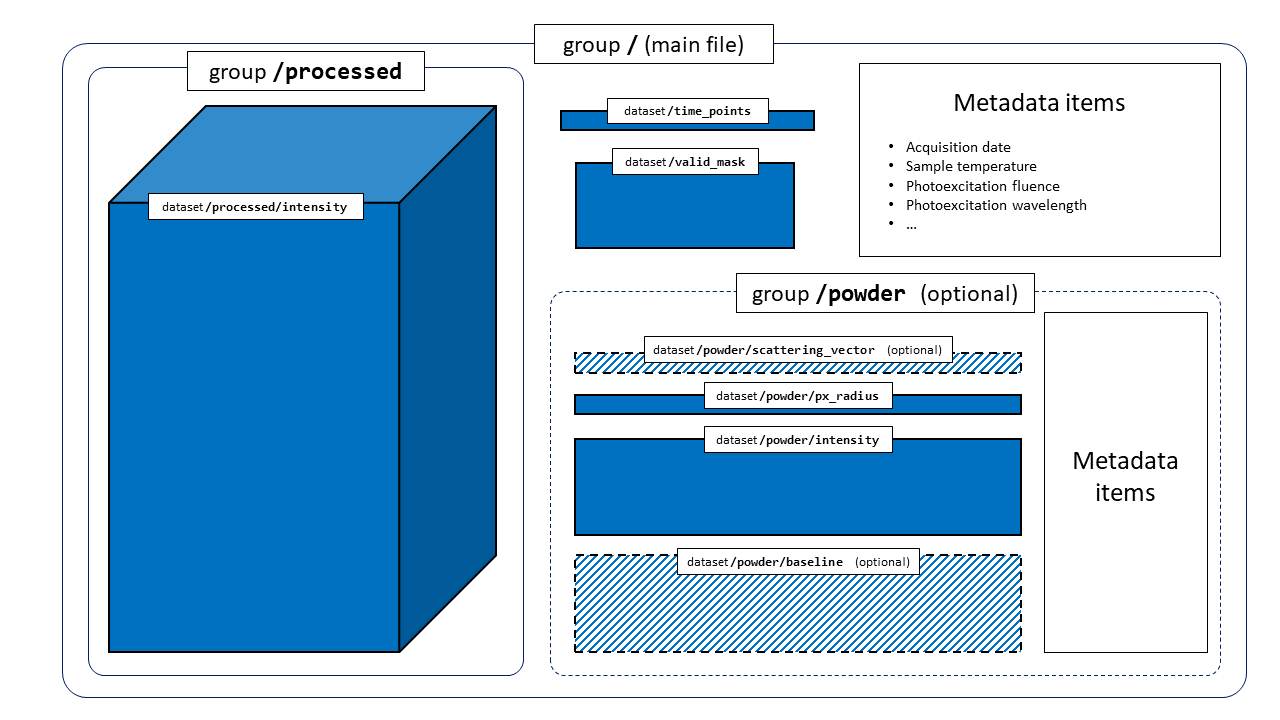
HDF5 layout¶
DiffractionDataset instances (and by extension, PowderDiffractionDataset instances) are a specialization of HDF5 files.
Therefore, it is possible to inspect and manipulate instances with any other tool that has bindings to the HDF5 libraries. The
HDF5 layout is presented below.
To look at your own data, don’t try to create such an HDF5 file by hand! Take a look at our plugin infrastructure (see Dataset Plug-ins).